

While the internet is laughing at a shocking “0%” score for OpenAI’s flagship model on the new CritPt benchmark, a bigger story is hiding in the data: DeepSeek V3.2 Speciale has officially outperformed GPT-5.1 and Claude Opus 4.5 to become the second-smartest model in the world for hard science.
The “Impossible” Test: What is CritPt?
Released this month by a coalition of over 50 physicists from 30 institutions, the CritPt (Critical Point) benchmark is designed to be “unsolvable” by standard AI. Unlike normal tests that ask textbook questions, CritPt forces AI to solve unpublished, research-level problems in quantum mechanics and condensed matter physics.
The Shocking Result
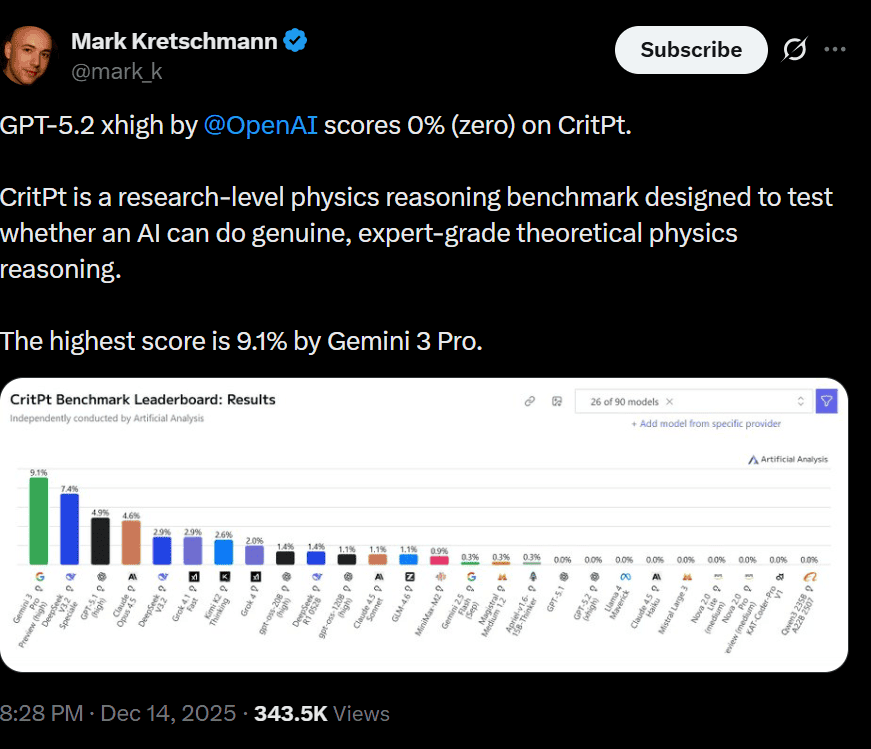
According to the verified leaderboard published by Artificial Analysis, the rankings have shifted dramatically. Screenshots captured from the live leaderboard earlier today show a new runner-up:
- Gemini 3 Pro: 9.1% (The current king)
- DeepSeek V3.2 Speciale: 7.4% (The new runner-up)
- GPT-5.1 (High): 4.9%
- Claude Opus 4.5: 4.6%
- GPT-5.2 (xhigh): 0.0%
Why did GPT-5.2 Score 0%?
The “0%” score for OpenAI’s newest GPT-5.2 xhigh model appears to be a technical failure rather than a lack of intelligence. Reports suggest the model’s new “Extra High” reasoning mode—which takes minutes to “think” before answering—is triggering safety refusals or timeouts when faced with CritPt’s complex, open-ended physics scenarios.
The Real Winner: DeepSeek V3.2 Speciale
The massive news for developers and businesses is DeepSeek’s performance. The “Speciale” variant is a specialized “pure reasoning” model released on December 1st. It was designed specifically for math and code, having already won gold medals in the 2025 International Math Olympiad (IMO).
This efficiency is exactly why developers are now using DeepSeek to build offline local agents that run without internet. (We are currently testing a tool that lets you run this exact intelligence on your laptop—check out our upcoming guide on How to Build a Private DeepSeek Agent).
Why This Matters for You
- Cost: DeepSeek V3.2 Speciale costs roughly 10x less to run than the proprietary giants like Gemini 3 Pro or GPT-5.
- Access: Unlike Google’s restricted “Pro” models, DeepSeek’s model is open for developers to build on via API.
The Verdict
If you need an AI for DeepSeek tutorials, stick to the basics. But if you are doing complex research, coding, or scientific analysis, DeepSeek V3.2 Speciale is now the verified “Budget King”—beating OpenAI’s best for a fraction of the price.
FAQ: Everything You Need to Know About DeepSeek V3.2
Is DeepSeek V3.2 Speciale free to use? Yes, mostly. Because DeepSeek V3.2 is an open-weights model, developers can run it locally for free if they have the hardware. For API users, it is significantly cheaper than OpenAI’s GPT-5 models.
Why did GPT-5.2 score 0% on CritPt? The 0% score is likely a technical timeout. The new “xhigh” reasoning mode takes a long time to think. On the CritPt benchmark, this delay caused the system to “refuse” to answer, resulting in a zero score.
How is DeepSeek V3.2 different from the normal version? The “Speciale” version of DeepSeek V3.2 is fine-tuned specifically for complex reasoning, math, and physics. It sacrifices some creative writing ability to be smarter at logic puzzles, which is why it excels on tests like CritPt.
Can I run DeepSeek V3.2 on my laptop? Yes. While the full 671B parameter model requires massive hardware, DeepSeek V3.2 comes in smaller “distilled” sizes (like 1.5B and 7B) that can run on standard laptops using tools like Ollama.
1 thought on “OpenAI Scores 0%? DeepSeek V3.2 Speciale Beats GPT-5.2 in New “Impossible” Physics Test”